开元棋app官方下载 AI「脑补」画面太强了!李飞飞团队新作ZeroNVS,单个视图360度全场景生成
[新的Zhiyuan简介]斯坦福大学和Google团队提出了Zeronvs,可以实现360度尝试合成单个图像零样本的尝试。
最近,已经使用3D感知扩散模型进行了无数研究,以训练模型开元棋盘app官方版下载_开元棋盘app官网版下载-跑跑车,然后对单个对象进行SDS蒸馏。
但是,从来没有意识到它可以真正实现“场景级”的图像产生。
现在,斯坦福·利费维(Stanford Li Feifei)和谷歌团队(Google Team)打破了这一唱片!
例如,输入从一定角度拍摄的客厅的照片,整个客厅的外观将出现。
具有非常角度角度的房屋的另一个转角图也会创造出意外的空间。
在室内和室外也有各种物体的完整场景图片。

看到这一点,人们不得不大声疾呼AI是如此强大!
那么,这是如何实现的?
3D感知扩散模型 - 亮度
在最新论文中,斯坦福大学和Google研究人员介绍了3D感知的扩散模型-Zeronvs。
纸张地址:
生成图像时,单图像,360度新视图合成(NVS)模型应是现实的和多样的。
合成图像应该看起来很自然,而3D对于我们来说是一致的,它们还应捕获许多不可观察区域的可能解释。
过去,这个具有挑战性的问题经常在一个对象中研究,即使没有上下文,即对真实性和多样性的要求也被简化了。
最近的研究依赖于高质量的大规模数据集(例如OBJAVERSE-XL)使有条件的散射模型从新的角度从新角度产生逼真的图像,然后通过SDS蒸馏进行采样以提高3D一致性。
同时,由于图像多样性主要反映在背景中,而不是在物体中,因此对背景的无知会显着降低合成多样的图像的效果。
实际上,大多数以对象为中心的方法不再将多样性视为一种衡量标准。
但是,在复杂的实际场景中生成新的透视图综合是一个更困难的问题,目前没有包含完整场景真实信息的大规模数据集。
研究人员对研究的背景进行了建模,以产生不同的结果。
在Zeronvs中,作者开发了新技术来预测单个真实图像的场景,并基于3D感知的扩散模型训练(Zero-1-1-to-3)和SDS蒸馏(DreamFusion)的先前工作。
特定方法
研究人员着手从单个真实图像中综合场景级的小说视野。
与以前的工作相似,我们首先训练扩散模型
执行新型视图合成开元ky888棋牌官网版,然后使用它执行3D SDS蒸馏。
与以前的工作不同,作者专注于场景而不是对象。
场景提出了一些独特的挑战。首先,以前的研究使用了相机和比例的表示,这些相机和比例对现场来说是模糊的或不充满焦虑的。
其次,先前研究的推理过程基于SD,该过程已经知道了模式崩溃问题,并且在现场反映了预测视图中的背景多样性。
与以前的工作相比,研究人员试图通过“改善场景的表示”和“推理程序”来应对这些挑战。
在此公式中,M的输出和单个图像的输入
是该模型可以用于查看合成的唯一信息。
代表视图合成的对象
如下图所示,3DOF摄像机的姿势捕获了指向原点的相机高度,方位角和半径,但不能表示相机的滚动(如图所示)或沿空间中任何方向的摄像机。
具有此参数化的模型无法在实际数据上训练,并且许多相机姿势不能以3DOF姿势完全表达。
代表了视图合成的常见场景
对于场景,研究人员应使用具有6个自由度的摄像头表示,可以捕获所有可能的位置和方向。
捕获六个自由度的相机参数化的直接选择是相对姿势参数化。研究人员认为,视野也可以用作额外的自由度,并将这种组合称为“ 6DOF+1”。
M 6DOF+1的一个有吸引力的功能是,它对场景的刚性转换具有不变性,因此您可以获得:
对于每个归一化方案,Zeronv中多个样品的Sobel边缘图方差的热图。研究人员提出的方案M 6DOF+1降低了尺度模糊引起的随机性。

通过SDS锚定提高多样性
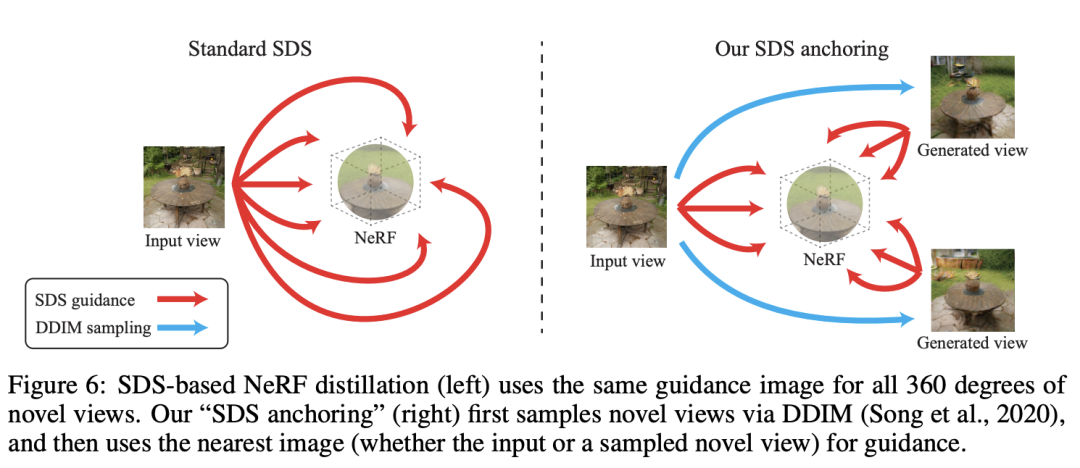
基于SDS的NERF蒸馏(左)使用所有360度新视图的启动图像。
作者的“ SDS锚定”(右)首先通过DDIM示例新视图,然后将最近的图像(无论是输入还是采样新视图)作为指南。
实验结果
在特定的评估中,研究人员使用一组标准的新视图合成指标来评估所有方法:PSNR,SSIM和LPIP。
由于PSNR和SSIM具有已知缺陷,因此研究人员对LPIP进行了更高的评价,并确认PSNR和SSIM与问题设置中的性能没有良好的相关性,如图7所示。
结果如表1所示。
首先,我们将其与基线方法DS-NERF,Pixelnerf,Sinnerf和Dietnerf进行了比较。
尽管所有这些方法均在DTU上进行了培训,但研究人员从未在DTU上接受过培训,而是获得了最先进的LPIPS零样本。
一些定性比较如图8所示。

DTU场景仅限于相对简单的前向场景。
因此,研究人员还引入了一个更具挑战性的基准数据集,即MIP-NERF 360数据集,以基准单个图像的360度视图综合任务。
研究人员将此基准用作零样本基准测试开元棋app官方下载,并在混合数据集上训练了3个基线模型,以比较零样本的性能。
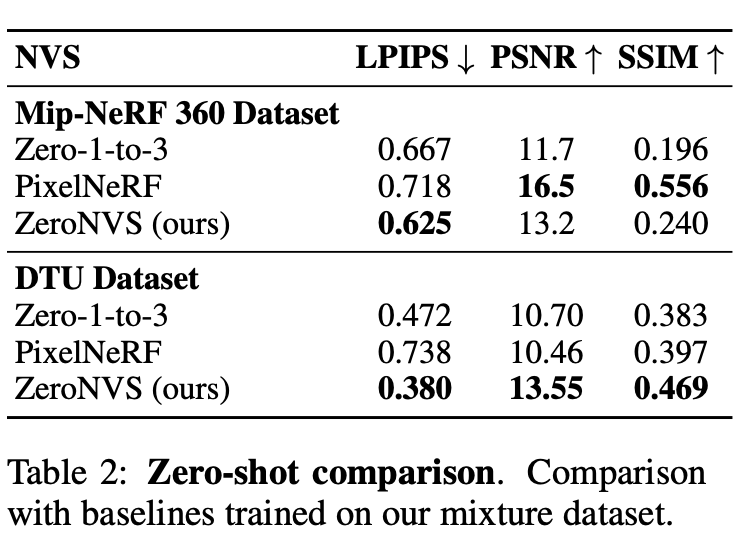
限制了这些零样本模型,该方法远远超过了该数据集的LPIP。在DTU上,新方法在所有指标上,不仅是LPIPS上的零1-3和零样本Pixelnerf模型,如表2所示。
作者的介绍
凯尔·萨金特(Kyle Sargent)
自2022年秋季以来,斯坦福大学的一名博士生,他曾在斯坦福人工智能实验室工作,他的指示是Jiajun Wu和Feifei Li的指导。
他还曾在Google Research担任学生研究员。

参考:
 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论